This is my attempt of a past Kaggle competition Lyft 3D Object Detection for Autonomous Vehicles, using the concept of frustum-pointnet to solve this past Kaggle competition.
This is an example of the classifed results:
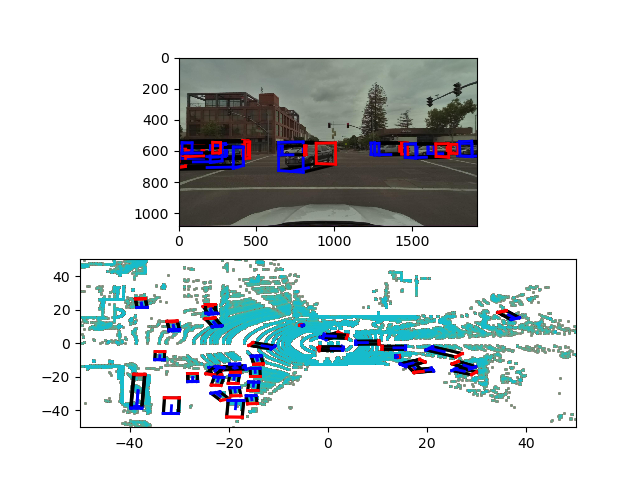
Result
This work is still in progress. The result does not seem too bad if observing by eye. However, the score is not as good as the baseline score by using image segmentation of top-view lidar data (e.g. this work). Because this model generates the frustum proposals from camera images, objects behind other objects are not well shown on 2D images, causing some loss in this model. Although this implementation does not exceed the performance of a simple top-view model, I did learn a lot of experience handling pointnet data and computer 3D graphics.
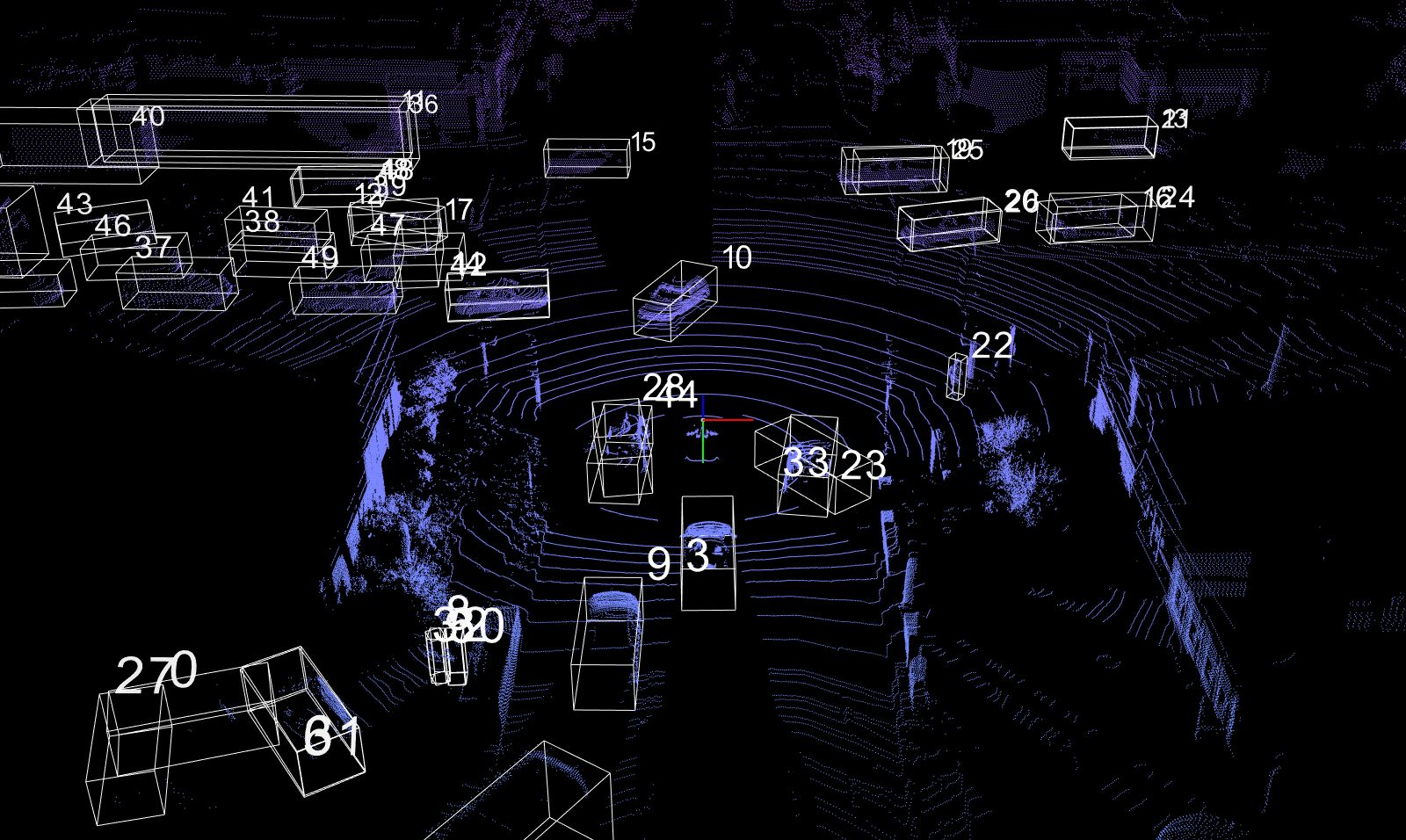
The implementation
Generate frustum proposal from images
The outline of the model is below:
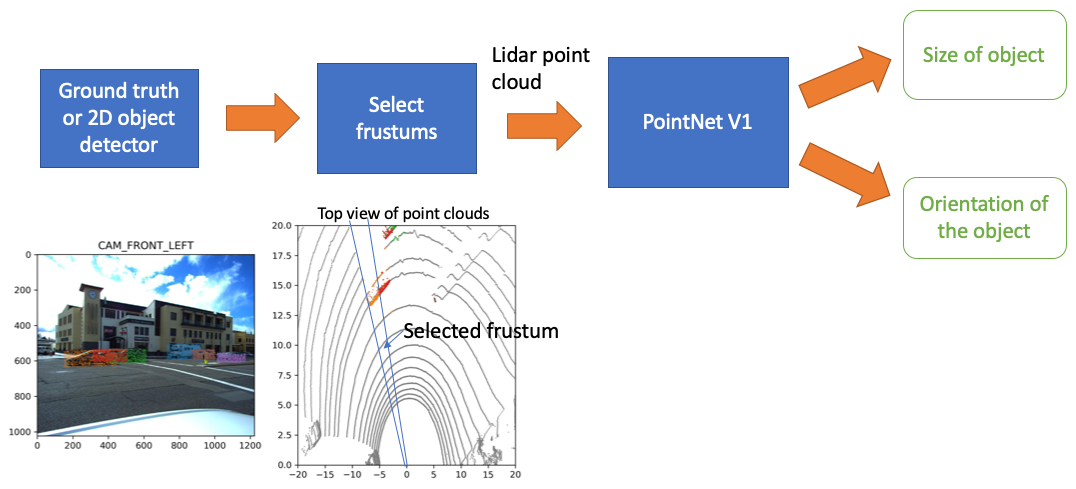
Here's some details of the implementation
Object detection model
The frustum proposal is generated from a object detector. I trained Fast RCNN-ResNET detector using Tensorflow object detection API.
The following image is an example of the image:
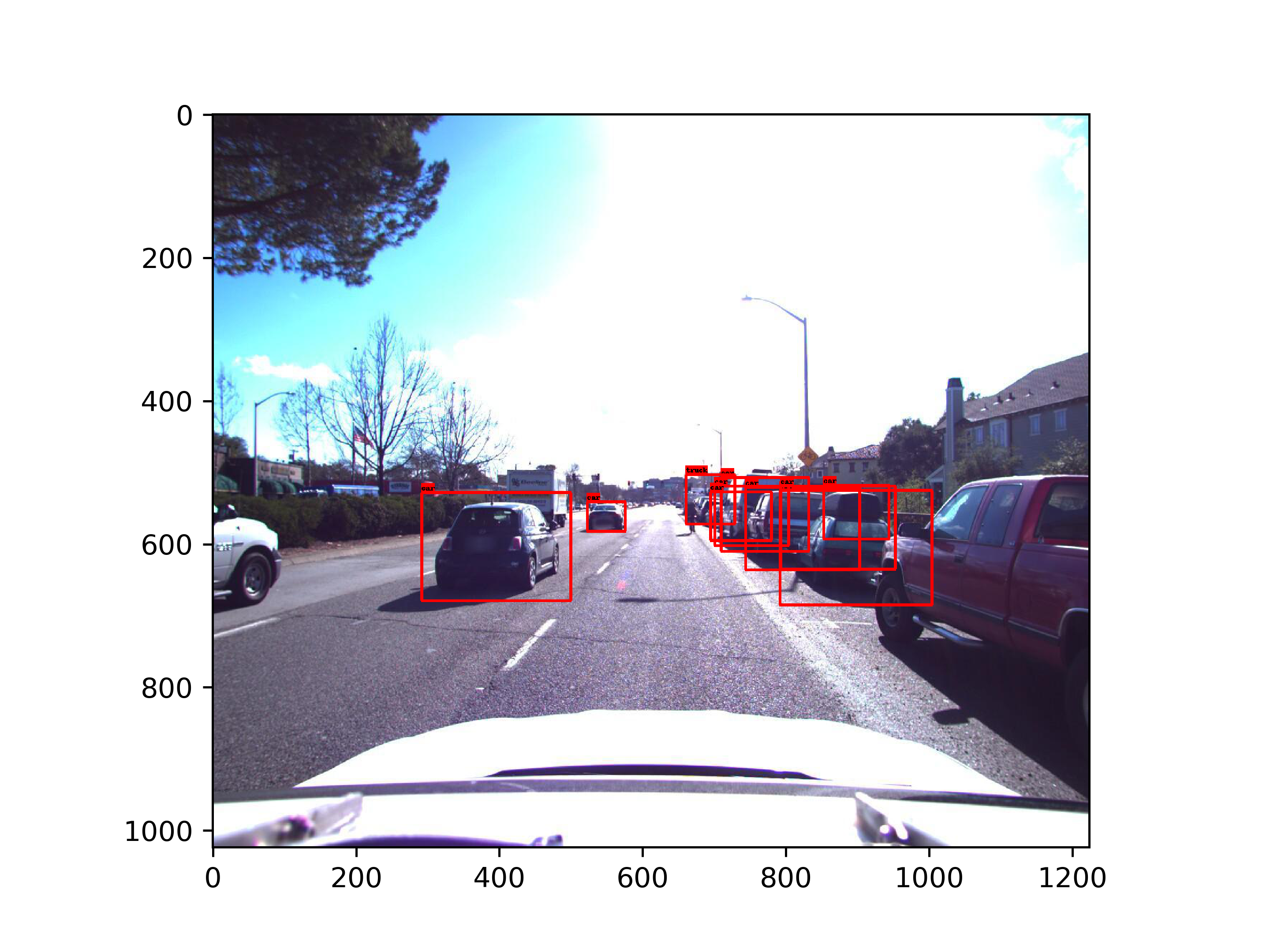
compared with the point cloud extracted from ground truth:
Frustum extraction
The frusum proposals was extracted all cameras images of a certain time stamp. These data were saved to a tfrecord files for training a PointNetV1 model. The original paper trained the model for many days. I only trained a few epochs for a few hours because of insuffcient budget.
PointNetV1
I altered the code of frustum-pointnet to train the data via the prepared tfrecord files.
Analysis and further improvement ideas
The IoU precision is not satisfactory. The precision score of each IoU levels are:
iou level:0.5, avg precision: 0.01156315990772716
iou level:0.55, avg precision: 0.008525362114315115
iou level:0.6, avg precision: 0.005816150268591333
iou level:0.65, avg precision: 0.0038102846985294658
iou level:0.7, avg precision: 0.0023121225957451587
iou level:0.75, avg precision: 0.001109161883024114
iou level:0.8, avg precision: 0.00016343784202644128
The reason is that this approach generates frustum proposals from 2D images. As a result, object behind another object is misclassified using a 2D object detector, as we can see in the above figures. Also, the averaged precisions drops quite significantly with the IoU levels, indicating that the predicted boxes are not very accurate. Training the PointNet for more epochs would certainly help.
- Add point cloud proposals using a top-view.
- Use image augmentation to make the classes of the data more balanced, this would increase the precisions of the class of objects that have fewer occurrences, such as "pedestrians" or "other vehicles"
Code
The source code of this project: Source code.